
Tools and Technologies
AWS EC2
Our project was deployed onto an AWS EC2 instance to make it publicly available.
React.js
React.js was used to create the frontend web display for the project. It was chosen for its ease of use in development and ability to deploy dynamic pages for different users.
Express.js
Express.js is a backend option that can allow for easy availability of routes. This setup allowed us to minimize the number of requests that the front end had to make at once.
Scikit-Learn
Scikit-learn was used for all of the machine learning predictions. We chose this for its ease of use, as well as the fact that it was able to handle all of our needs in a lightweight package. Specifically we chose to focus on the use of SVMs (Support Vector Machines) for our predictions.
Visual Crossing Weather API
The Visual Crossing Weather API was used to scrape historical data and forecasted data for upcoming games. This was the main option that enabled us to have specific enough weather data for the length of games as well as give accurate data for the games still upcoming.
Software Architecture
An overview of the system architecture can be seen below:
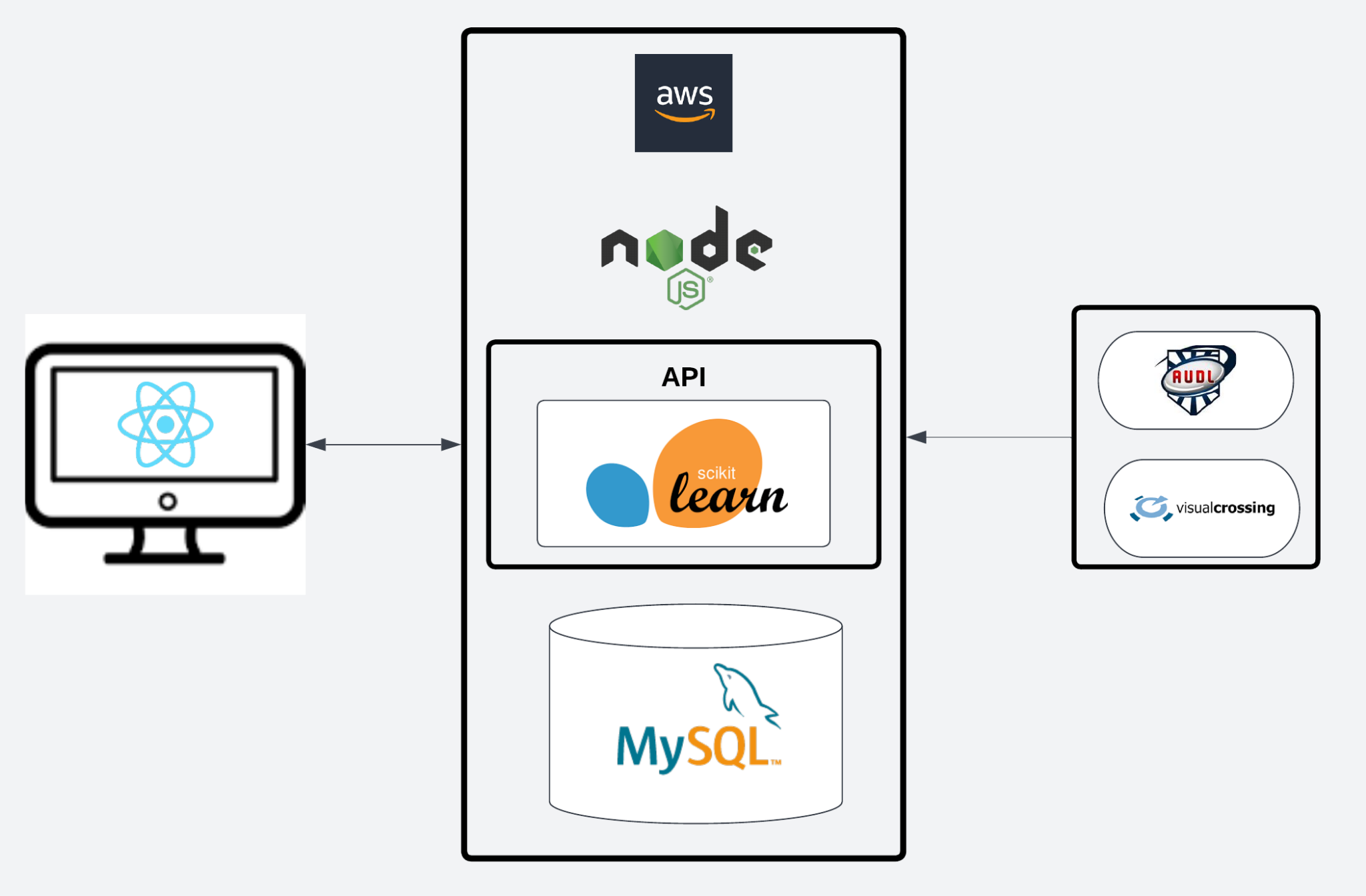 There are three key areas: data, server-side computing, and front end.
There are three key areas: data, server-side computing, and front end.
Data
We retrieved all our data from two sources: the AUDL backend and the Visual Crossing Weather API. From the AUDL backend, we scraped all available player, team, and historical game records. From the visual crossing weather API, we scraped historical weather data for each past game, in 15 minutes intervals to create an average over the length of the games.
All of the data scraping was done by using either Node.js or Python requests. Additonally, we added recurring scraping - when new games are added to the schedule, they are added to our database as upcoming and forecasted weather data is used to create a prediction for the match.
All of our data was stored into a MySQL database.
Server-Side
Our backend was run with Node.js. This was also used to help manage the database over time and is what automates future scraping.
Alongside the Node.js backend, we ran a Python Flask API that wrappped around our machine learning prediction algorithm. By wrapping the algorithm inside of an API, this allowed us to run our machine learning in one language (Python) and the rest of our backend in a different language (Node.js). This also greatly helped us during testing, as the prediction engine could be directly available without having to communicate with other parts of the application.
Our machine learning algorithm was implemented with the Python Scikit-learn library. This enabled us to both develop and calculate predictions quickly.
All of this (Node.js backend, Flask API + ML predictions, MySQL database, data scraping and automation) was done on an AWS EC2 instance.
Front End
The front end was developed with React.js. This is where users can actually interact with the UPE to view and make their predictions. Inputs were inspired to enable as much customization as possible for users when making their predictions.